Web scraping with Python using Selenium
The program’s main purpose is scrape data from a job seeking web site indeed.com. Our program takes 2 input variables called the job and the location. Location is an optional variable it can be stay unfilled or you can type remote for finding the remote jobs. The output is a csv file with three features; company name, job header, job description. You can work with this text data and do nlp operations. It’s up to you. Be creative.
Now let’s take a look to the code. First you might need to install some libraries. So open up your terminal and type below lines
$-> pip install pandas
$-> pip install selenium
If you installed the libraries we can begin. First we import our libraries and classes that we’ll needed.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager #For windows you can comment it out
import time
import pandas as pd
#For windows run below
PATH = "C:\Program Files (x86)\chromedriver.exe"
driver = webdriver.Chrome(PATH)
#For mac run below
driver = webdriver.Chrome(ChromeDriverManager().install())
Now time to define our input variables
job = str(input("JOB:"))
location = str(input("LOCATION:"))
Next we define three lists to store our data. After the storing the data we will use these three lists to convert our data to a csv file.
company_list = []
job_list = []
job_desc_list = []
We’ll use four function to achieve our goal.
Function 1
def create_df(*args):
df = pd.DataFrame({
"company":args[0],
"job_header":args[1],
"job_description":args[2]
})
return df
In above function you dont have to use args to get parameters. You can give your parameters as usual. As you see the function takes parameters and return a dataframe. We will use it later.
Function 2
def go_indeed(job,location):
driver.get("https://ca.indeed.com/")
main = WebDriverWait(driver,10).until(
EC.presence_of_element_located((By.ID,"ssrRoot"))
)
text_input = main.find_element_by_id("text-input-what")
text_input.send_keys(JOB)
if len(LOCATION) != 0:
location_input = main.find_element_by_id('text-input-where')
location_input.send_keys(Keys.CONTROL,'a')
location_input.send_keys(Keys.BACKSPACE)
location_input.send_keys(LOCATION)
try:
find_jobs = main.find_element_by_xpath('//*[@id="jobsearch"]/button')
except:
find_jobs = main.find_element_by_xpath('//*[@id="whatWhereFormId"]/div[3]/button')
find_jobs.click()
This function takes two parameters. It directly goes to ca.indeed.com and clicks “find jobs” button using your input variables.
Function3
def get_page():
main = WebDriverWait(driver,10).until(
EC.presence_of_element_located((By.ID,"resultsBodyContent"))
)
# Get company names and JOB titles
job_titles = main.find_elements_by_tag_name("h2")
company_names = main.find_elements_by_class_name("companyName")
# Add the data to each lists
for i in range(len(job_titles)):
job_titles[i].click()
title = job_titles[i].text.replace('new\n','')
company = company_names[i].text
time.sleep(1)
try:
job_desc = main.find_element_by_id("vjs-desc")
except:
iframe = driver.find_element_by_xpath('//*[@id="vjs-container-iframe"]')
driver.switch_to.frame(iframe)
job_desc = driver.find_element_by_id("jobDescriptionText")
job_desc_list.append(job_desc.text)
driver.switch_to.default_content()
job_list.append(title)
company_list.append(company)
After clicking the find jobs button, we goes to a page with full of job postings. In this function we click the header of each job and got the company name, job header and job description. The reason of clicking is that the job description is a window which shows up after the clicking the header. So we click in order to get job description. Take a look to the below pictures.
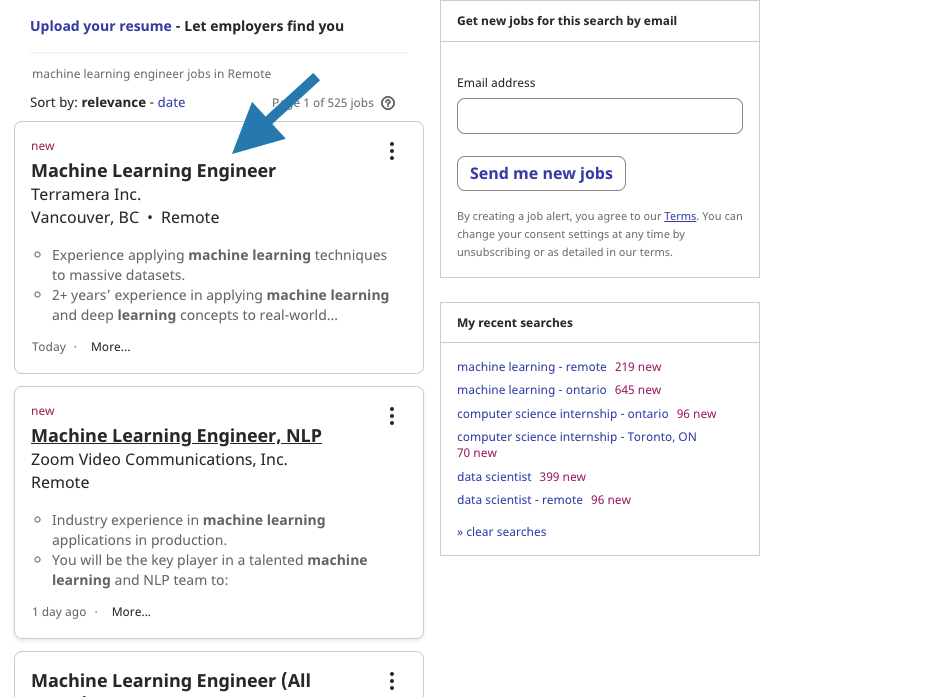
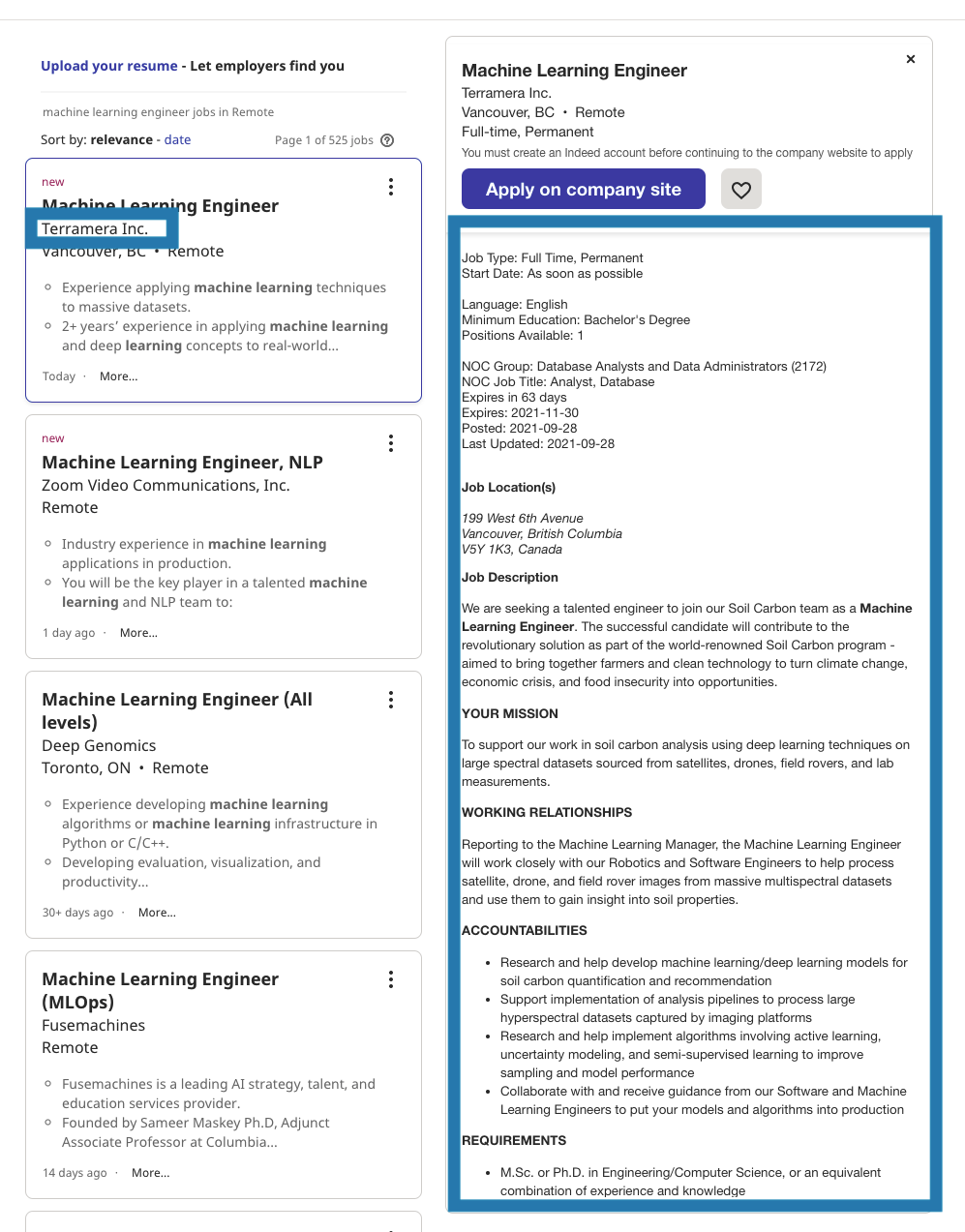
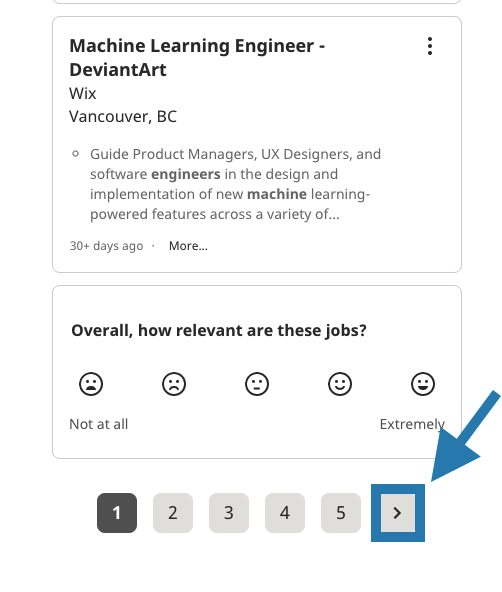
Function 4
We run get_page function in this function. Also we click the forward button to go to the next page. Lastly, we create and save our csv file in this function.
def get_data():
try:
for i in range(10):
time.sleep(1)
get_page()
#Click the forward button
if i == 0:
button = WebDriverWait(driver,10,)\
.until(EC.presence_of_element_located((By.CLASS_NAME,'np')))
else:
try:
#EDIT HERE IF YOU HAVE PROBLEM SARPER (THE XPATH IS DIFFERENT)
button = WebDriverWait(driver,10,)\
.until(EC.presence_of_element_located((By.XPATH,'//*[@id="resultsCol"]/nav/div/ul/li[5]/a/span')))
except:
break
button.click()
driver.refresh()
finally:
#Create the dataset
df = create_df(company_list,job_list,job_desc_list)
job_str = ''.join(x for x in JOB.title() if not x.isspace())
if len(LOCATION) != 0:
location_str = ''.join(x for x in LOCATION.title() if not x.isspace())
df.to_csv((f"{job_str}_{location_str}.csv"),index=False)
driver.quit()
To run all functions properly we just call two function:
go_indeed(job,location)
get_data()
This is a sample of a csv file that we scraped from the website
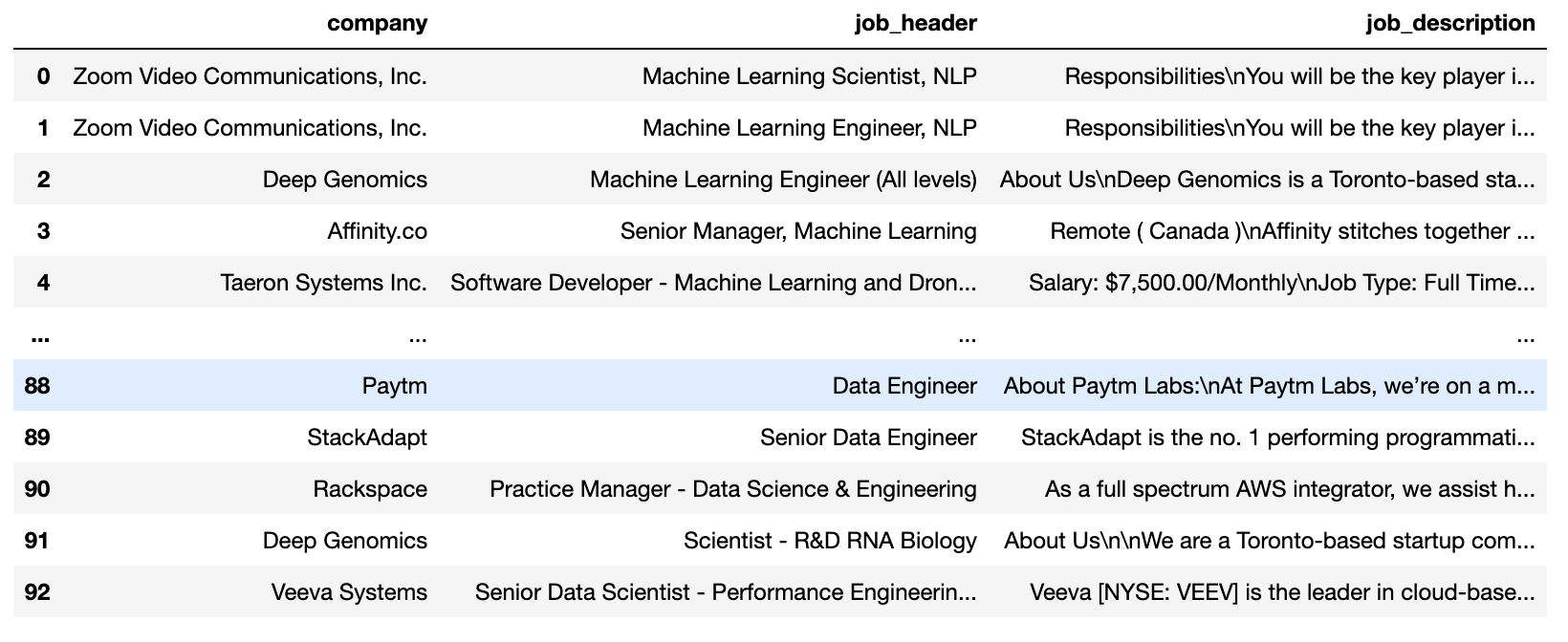
We created this program with my friend Khue. You can find our repo and her github account by clicking.